復旧の方法はいくらでもありますが、その一つとして紹介します。
Linuxをいじっていると、復旧の手段がなくなるまでシステムを破損することがあると思います(私はよくあります)。Linuxは何でも自由にいじれます。しかし自由であるということは、責任を伴うということです。
私が(今回)やってしまったのは
1. /dev/loop0にルートをマウントした
2. マウントしたままfsckをした (ERROR!)
でした。
マウントしたままであったのをしばらく気づかず、その後も色々操作をしてしまい、複数のシステムファイルをどこかにやってしまいました(正確にはファイルのinodeが消えてしまったのでしょう)。
結局Ubuntuをインストールしなおして、必要なデータを元のUbuntuから取り出し、そちらはアンインストールすることにしました。
データの取り出し方は、Linux to Linuxは非常に簡単で、
sudo mkdir /mnt
sudo mount /path/to/root.disk /mnt
sudo cp -r /mnt/home/user/files /home/user
sudo umount /mnt
とすればディスクイメージからファイルを取り出すことができます。
何をやっているかというと、
1. sudo mount /path/to/root.disk /mnt
ディスクイメージを/mntにマウント。これによって/mntからディスクイメージにアクセスすることができる
2. sudo cp -r /mnt/home/user/files /home/user
/mnt以下の仮想ファイルの必要なものをコピーしてくる
3. sudo umount /mnt
マウントしたイメージを戻す
といった感じです。
そういう訳で、root.diskのバックアップは定期的にとっておくと便利だと思います。Ubuntuはファイルサイズもそんなに大きくならないので、時間もそんなにかかりません(不思議なことにUbuntuを使っているとHDDをあまり使いません。多分ゲームをあまりダウンロードしなくなるからでしょう。)。
もっとも効率良くLinuxを知る方法は、Linuxをクラッシュさせ、復旧を試みることだというのが有名な話です。そういう意味でこの方法は再起不可能なまでにクラッシュさせた場合に使うべき方法かもしれません。あるいは復旧にかける時間がない時などに、手早く必要なファイルを取り出せます。
こういうことを経験していくと、逆にWindowsの設計思想を理解できるようになるように思えます。
Windowsはシステムファイルを完全に隠蔽しているのでなかなか(意図せず)再起不能にさせることができないのです。
2014年8月31日日曜日
2014年8月30日土曜日
MSVC2012はC++11のclass member initializationに未対応の模様
C++11からclass member initializationが導入されましたがMSVC2012は対応していない模様。
class member initializationはC++のクラスをはじめて触る人が必ずやる初期化でしょう。
・C++11
メンバの宣言に初期化を定義することが出来、これによってクラスCのオブジェクトは全てx=7で初期化されることになります。これはC++11以前は以下のように記述する必要がありました。
・C++11以前
全てのコンストラクタで宣言しなければならないということと、、xの宣言と初期化が別の行に書かれることなどの理由からC++11でclass member initializationが導入されました。
しかしながらこのclass member initialization、MSVC2012は対応していない模様。
MSのドキュメントに詳しく記載されています。
Support For C++11 Features (Modern C++)
class member initializationはC++のクラスをはじめて触る人が必ずやる初期化でしょう。
・C++11
class C { int x = 7; //これ public: C(); };
メンバの宣言に初期化を定義することが出来、これによってクラスCのオブジェクトは全てx=7で初期化されることになります。これはC++11以前は以下のように記述する必要がありました。
・C++11以前
class C { int x; public: C() : x(7) {} };
全てのコンストラクタで宣言しなければならないということと、、xの宣言と初期化が別の行に書かれることなどの理由からC++11でclass member initializationが導入されました。
しかしながらこのclass member initialization、MSVC2012は対応していない模様。
MSのドキュメントに詳しく記載されています。
Support For C++11 Features (Modern C++)
実際にC++Standardに従っているコンパイラはあまりないということでしょう。c++11対応といってもその機能の全てを網羅しているとは限らない。
リンク先の表を見てみると、よく使われる機能から順に実装されている様子。
class member initializationも2013から対応しています。
MSVC2012依存のプロジェクトはご注意を。
C++11のこういった機能の追加はコンパイラ技術の向上の賜物でしょう。C++の様々な非直感的な仕様は実はコンパイル時(構文解析時)の制約の為なのですが、だんだんと進歩していっているようです。
C++11のこういった機能の追加はコンパイラ技術の向上の賜物でしょう。C++の様々な非直感的な仕様は実はコンパイル時(構文解析時)の制約の為なのですが、だんだんと進歩していっているようです。
2014年8月28日木曜日
Ubuntu(Linux)のリカバリーモードで文字化けする場合
残念ながら、Linuxは日本語にやさしくありません。
iBusの導入も漢字圏などの表意文字圏に対するdisregardと言っても過言ではないでしょう。
まぁ日本語にやさしくないというよりかは、英語以外に対するサポートが少ない、というのが正しい見解でしょう。
日本語を導入したUbuntuをリカバリーモードで起動すると文字化けします。
エラーメッセージから何から全て
sudo: PAM ■■■■■■■■■■■■■■
としかかかれないので何が何だか分かりません。これではリカバリーは出来ないです。
しかし日本語自体を消すのも負けた気分です。
リカバリーモード中だけ英語にする方法があります。
/usr/share/recovery-mode/recovery-menu
を開き、
# main
と書かれた行を見つけたら
export LANGUAGE=C
# main
とCを指定しましょう。
するとどういう訳か上手くいき、リカバリーモードが英語になります。(治らない場合はリブートしてみましょう。)
ちなみに私がリカバリーモードを使っているのは間違えてlibz.so.1を消してしまったためです。
libz.soはアプリケーションを管理しているライブラリで、これがなくなるとapt-getもwgetも何も出来なくなってしまいます。libz.soはgnome3のppaに置いてあるので取ってくればよい訳ですが、apt-get, wgetも何も使えなくなるのでそれも出来ない、ロック状態に陥ってしまいました。
この場合、LiveCDを持ってきてlibz.soをコピーすることで解決できます。
iBusの導入も漢字圏などの表意文字圏に対するdisregardと言っても過言ではないでしょう。
まぁ日本語にやさしくないというよりかは、英語以外に対するサポートが少ない、というのが正しい見解でしょう。
日本語を導入したUbuntuをリカバリーモードで起動すると文字化けします。
エラーメッセージから何から全て
sudo: PAM ■■■■■■■■■■■■■■
としかかかれないので何が何だか分かりません。これではリカバリーは出来ないです。
しかし日本語自体を消すのも負けた気分です。
リカバリーモード中だけ英語にする方法があります。
/usr/share/recovery-mode/recovery-menu
を開き、
# main
と書かれた行を見つけたら
export LANGUAGE=C
# main
とCを指定しましょう。
するとどういう訳か上手くいき、リカバリーモードが英語になります。(治らない場合はリブートしてみましょう。)
ちなみに私がリカバリーモードを使っているのは間違えてlibz.so.1を消してしまったためです。
libz.soはアプリケーションを管理しているライブラリで、これがなくなるとapt-getもwgetも何も出来なくなってしまいます。libz.soはgnome3のppaに置いてあるので取ってくればよい訳ですが、apt-get, wgetも何も使えなくなるのでそれも出来ない、ロック状態に陥ってしまいました。
この場合、LiveCDを持ってきてlibz.soをコピーすることで解決できます。
2014年8月26日火曜日
写実性と存在感
土偶は人間を模した形をしているが、写実的な人間の形からは大きく離れている。人間を模しているが、写実的な人間の像を作ることを目的としていなかったのだろう。技術的な問題から美しい写実的な像を作ることは不可能だったかもしれないが、土偶のそれは写実性に興味のない造型であるだろう。しかし同時に、猿でもなく犬でも他の何者でもなく、人間を模したものであるという確信が持てるものだ。人間を象りながら、人間とある程度の距離を置いているのだ。
写実的な画像の描画が可能になった現代においても、多くのアニメは写実的ではない。やはりここで起きているのは技術的な問題ではないのだ。では何故アニメは写実性を持たないのだろうか。それは、存在感を持たせる為である。
存在感とは写実性に担保されるものではない。写実的であっても必ずしも存在感は得られない。むしろ、土偶やアニメといったものに存在感を与えるには写実性はむしろ有害であるだろう。土偶は偶像である。豊穣や子孫繁栄などを祈る為に崇拝したと言われている。いずれにしても、それは非日常にある存在である。土偶という精霊が「存在」するのは、その詳細を知り得ないからである。どのような姿形をしているのか、本当に豊穣をもたらすのか、そのようなことを知り得ないから存在する。アニメも同様の議論が成り立つ。詳細が「存在しない」からこそ、そこに存在感が現れるのだ。
もう一つの問題は、写実的であれば写実的であるほど、細部が要求されることである。より元となるものに近しい写像であるほど、小さな違いが大きな違和感になって現れる。この違和感とは存在感をかき消してしまうものである。
土偶やアニメが写実性をもたないのは、それによってのみ存在感があり得るからである。
2014年8月6日水曜日
タダで読めるプログラミングの本
幸運にも世の中にはたくさんのfreeのプログラミングの本があります。これは情報科学の強みの一つでしょう。
一番有名なのは「計算機プログラムの構造と解釈」でしょうね。この本が和訳でタダになっているのは本当に素晴らしい。(絵柄はあれですけれど中身は美しいです。)

しかし思うに情報が氾濫していて、どこに良い情報があるかが分かりにくくなっているというのが現状でしょう。また、和訳版が少ないのもソフトウェア産業には問題でしょう。
free-programming-booksはfreeのプログラミング教材の情報をまとめようというプロジェクトです。プログラミングの本だったり、オンラインチュートリアル、あるいはビデオレクチャーなど。
日本語の本の情報もまとまっています。まだ少ないですが、新しい分野・言語の最初の一冊などを探すには便利だと思います。(かく言う私もcommitしています。)
こういうプロジェクトが広がっていくのは面白いですね。
一番有名なのは「計算機プログラムの構造と解釈」でしょうね。この本が和訳でタダになっているのは本当に素晴らしい。(絵柄はあれですけれど中身は美しいです。)
しかし思うに情報が氾濫していて、どこに良い情報があるかが分かりにくくなっているというのが現状でしょう。また、和訳版が少ないのもソフトウェア産業には問題でしょう。
free-programming-booksはfreeのプログラミング教材の情報をまとめようというプロジェクトです。プログラミングの本だったり、オンラインチュートリアル、あるいはビデオレクチャーなど。
日本語の本の情報もまとまっています。まだ少ないですが、新しい分野・言語の最初の一冊などを探すには便利だと思います。(かく言う私もcommitしています。)
こういうプロジェクトが広がっていくのは面白いですね。
2014年8月4日月曜日
Google Scholar Searcher開発中
pythonの練習の為、Google Scholarから目的の論文の近くにある論文を表示するスクリプトを開発中。
入力は論文の題名、URL か適当なキーワードにして、出力は関連する論文をグラフにまとめたものの予定。
作りかけなのはGoogle Scholarのボット検出に引っかかってしまうからです。今は引っかからないように毎回のアクセスに10~20秒時間をおいていますが、そうするとあまり大きな検索をすることが出来ません。大きな検索が出来ないとなると面白い結果が出せないので、ボット検出を避ける(なるべく穏便な)方法を探しています。(仮想IPアドレスを使って避けるという横暴(?)な方法もあるのですが、最終的にGoogle App Engineなどで公開したいので...正攻法はないものでしょうか。)
という訳で今のところcomputerに関連した論文を検索しているだけなので特に有用なスクリプトにはなっておりませんが、今のところの出力はこんな感じです。
キーワード「Computer」に関連した論文の関係を図示。ボット検出をくぐれたらGUIも整備することにします。
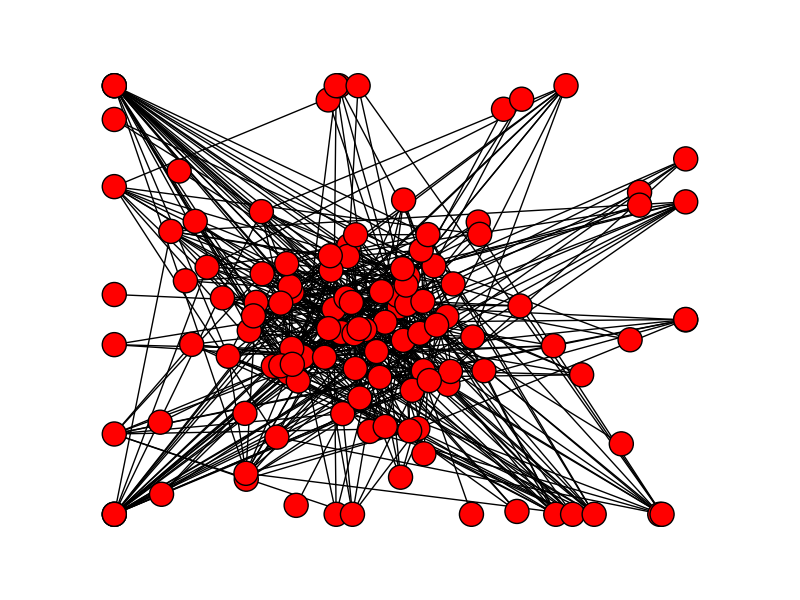
BeautifulSoup, networkxとmatplotlibをダウンロードする必要があります。
入力は論文の題名、URL か適当なキーワードにして、出力は関連する論文をグラフにまとめたものの予定。
作りかけなのはGoogle Scholarのボット検出に引っかかってしまうからです。今は引っかからないように毎回のアクセスに10~20秒時間をおいていますが、そうするとあまり大きな検索をすることが出来ません。大きな検索が出来ないとなると面白い結果が出せないので、ボット検出を避ける(なるべく穏便な)方法を探しています。(仮想IPアドレスを使って避けるという横暴(?)な方法もあるのですが、最終的にGoogle App Engineなどで公開したいので...正攻法はないものでしょうか。)
という訳で今のところcomputerに関連した論文を検索しているだけなので特に有用なスクリプトにはなっておりませんが、今のところの出力はこんな感じです。
キーワード「Computer」に関連した論文の関係を図示。ボット検出をくぐれたらGUIも整備することにします。
BeautifulSoup, networkxとmatplotlibをダウンロードする必要があります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 | # Parser from bs4 import BeautifulSoup import urllib2 # Network and Visualizing import networkx as nx import matplotlib.pyplot as plt # For polite bot import time import random import datetime url = "http://scholar.google.com" class CitationGraph: def __init__(self, title=''): self.g = nx.Graph() def add_result(self, result): self.g.add_node(result.title) for paper in result.papers: self.g.add_node(paper.title, paper = paper) self.g.add_edge(result.title, paper.title) def draw(self, path): nx.draw(self.g) plt.savefig(path + ".png") """ def extract(self, least_citations): if node['citations'] < least_citations: self.g.remove(node) """ """ The information of papers gain from specific URL. It also contains information about the context of the results. (ex. Cited or Related to the paper or a word search result) """ class Result: def __init__(self, query, title='', depth=1): self.title = title if 'cited' in query: context = 'cited' elif 'related' in query: context = 'related' else: context = 'search' self.query = query self.papers = [] self.search(1) def search(self, depth=1): time.sleep(random.randint(10, 20)) data = opener.open(url + self.query).read() soup = BeautifulSoup(data) for paper in soup.find_all('div', {'class' : 'gs_r'}): title = paper.find('div', {'class' : 'gs_ri'}).find('a').get_text() author = paper.find('div', {'class' : 'gs_a'}).get_text() abst = paper.find('div', {'class' : 'gs_rs'}).get_text() for link in paper.find_all('a'): if 'Cited' in link.get_text(): cited_link = link.get('href') citations = int(link.get_text().strip('Cited by ')) p = Paper(title, author, abst, cited_link, citations) self.papers.append(p) def print_papers(self): for paper in self.papers: paper.print_data() class Paper: def __init__(self, title, author, abst, cited_link, citations=0): self.title = title self.author = author self.abst = abst self.cited_link = cited_link self.citations = citations def print_data(self): print(self.title) print(self.author) print(self.abst) print(self.citations) print(self.cited_link) print('\n') """ Main Function """ opener = urllib2.build_opener() opener.addheaders = [('User-agent', 'Mozilla/5.0')] query = "/scholar?hl=en&q=computer&btnG=&as_sdt=1%2C5&as_sdtp=" r = Result(query, 'computer') r.print_papers() c = CitationGraph() c.add_result(r) for paper in r.papers: r2 = Result(paper.cited_link, paper.title) r2.print_papers() c.add_result(r2) t = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") c.draw('whole' + t) plt.show() |
2014年7月22日火曜日
知覚の諸問題

(SYNAPSEより)
Cognitive Neuroscience: The biology of the mind
Michael S. Gazzaniga, Richard B. Ivry and George R. Mangun
より5章Sensation and Perceptionの考察をまとめましたので、宜しければ。
文字認識とかでニューラルネットワークが使われますが、そこでのテクニックの多くは実際の人間の知覚を参考にしているところが多くあるのですね。
こういった認知科学の分野は、脳を分割していっても博物学的になるだけで面白い問題はないんじゃないかと思っていたんですが、意外と人間の脳というのは局所性があり、知能と「物質」を結びつけることができるようですね。
クオリアとかの主観的体験は観測することが出来ませんが、こういう機能論的な意味でのsensationを理解することはその礎になるのでしょう。
図表は全て上記論文より引用
登録:
投稿 (Atom)