残念ながら、Linuxは日本語にやさしくありません。
iBusの導入も漢字圏などの表意文字圏に対するdisregardと言っても過言ではないでしょう。
まぁ日本語にやさしくないというよりかは、英語以外に対するサポートが少ない、というのが正しい見解でしょう。
日本語を導入したUbuntuをリカバリーモードで起動すると文字化けします。
エラーメッセージから何から全て
sudo: PAM ■■■■■■■■■■■■■■
としかかかれないので何が何だか分かりません。これではリカバリーは出来ないです。
しかし日本語自体を消すのも負けた気分です。
リカバリーモード中だけ英語にする方法があります。
/usr/share/recovery-mode/recovery-menu
を開き、
# main
と書かれた行を見つけたら
export LANGUAGE=C
# main
とCを指定しましょう。
するとどういう訳か上手くいき、リカバリーモードが英語になります。(治らない場合はリブートしてみましょう。)
ちなみに私がリカバリーモードを使っているのは間違えてlibz.so.1を消してしまったためです。
libz.soはアプリケーションを管理しているライブラリで、これがなくなるとapt-getもwgetも何も出来なくなってしまいます。libz.soはgnome3のppaに置いてあるので取ってくればよい訳ですが、apt-get, wgetも何も使えなくなるのでそれも出来ない、ロック状態に陥ってしまいました。
この場合、LiveCDを持ってきてlibz.soをコピーすることで解決できます。
2014年8月28日木曜日
2014年8月26日火曜日
写実性と存在感
土偶は人間を模した形をしているが、写実的な人間の形からは大きく離れている。人間を模しているが、写実的な人間の像を作ることを目的としていなかったのだろう。技術的な問題から美しい写実的な像を作ることは不可能だったかもしれないが、土偶のそれは写実性に興味のない造型であるだろう。しかし同時に、猿でもなく犬でも他の何者でもなく、人間を模したものであるという確信が持てるものだ。人間を象りながら、人間とある程度の距離を置いているのだ。
写実的な画像の描画が可能になった現代においても、多くのアニメは写実的ではない。やはりここで起きているのは技術的な問題ではないのだ。では何故アニメは写実性を持たないのだろうか。それは、存在感を持たせる為である。
存在感とは写実性に担保されるものではない。写実的であっても必ずしも存在感は得られない。むしろ、土偶やアニメといったものに存在感を与えるには写実性はむしろ有害であるだろう。土偶は偶像である。豊穣や子孫繁栄などを祈る為に崇拝したと言われている。いずれにしても、それは非日常にある存在である。土偶という精霊が「存在」するのは、その詳細を知り得ないからである。どのような姿形をしているのか、本当に豊穣をもたらすのか、そのようなことを知り得ないから存在する。アニメも同様の議論が成り立つ。詳細が「存在しない」からこそ、そこに存在感が現れるのだ。
もう一つの問題は、写実的であれば写実的であるほど、細部が要求されることである。より元となるものに近しい写像であるほど、小さな違いが大きな違和感になって現れる。この違和感とは存在感をかき消してしまうものである。
土偶やアニメが写実性をもたないのは、それによってのみ存在感があり得るからである。
2014年8月6日水曜日
タダで読めるプログラミングの本
幸運にも世の中にはたくさんのfreeのプログラミングの本があります。これは情報科学の強みの一つでしょう。
一番有名なのは「計算機プログラムの構造と解釈」でしょうね。この本が和訳でタダになっているのは本当に素晴らしい。(絵柄はあれですけれど中身は美しいです。)

しかし思うに情報が氾濫していて、どこに良い情報があるかが分かりにくくなっているというのが現状でしょう。また、和訳版が少ないのもソフトウェア産業には問題でしょう。
free-programming-booksはfreeのプログラミング教材の情報をまとめようというプロジェクトです。プログラミングの本だったり、オンラインチュートリアル、あるいはビデオレクチャーなど。
日本語の本の情報もまとまっています。まだ少ないですが、新しい分野・言語の最初の一冊などを探すには便利だと思います。(かく言う私もcommitしています。)
こういうプロジェクトが広がっていくのは面白いですね。
一番有名なのは「計算機プログラムの構造と解釈」でしょうね。この本が和訳でタダになっているのは本当に素晴らしい。(絵柄はあれですけれど中身は美しいです。)
しかし思うに情報が氾濫していて、どこに良い情報があるかが分かりにくくなっているというのが現状でしょう。また、和訳版が少ないのもソフトウェア産業には問題でしょう。
free-programming-booksはfreeのプログラミング教材の情報をまとめようというプロジェクトです。プログラミングの本だったり、オンラインチュートリアル、あるいはビデオレクチャーなど。
日本語の本の情報もまとまっています。まだ少ないですが、新しい分野・言語の最初の一冊などを探すには便利だと思います。(かく言う私もcommitしています。)
こういうプロジェクトが広がっていくのは面白いですね。
2014年8月4日月曜日
Google Scholar Searcher開発中
pythonの練習の為、Google Scholarから目的の論文の近くにある論文を表示するスクリプトを開発中。
入力は論文の題名、URL か適当なキーワードにして、出力は関連する論文をグラフにまとめたものの予定。
作りかけなのはGoogle Scholarのボット検出に引っかかってしまうからです。今は引っかからないように毎回のアクセスに10~20秒時間をおいていますが、そうするとあまり大きな検索をすることが出来ません。大きな検索が出来ないとなると面白い結果が出せないので、ボット検出を避ける(なるべく穏便な)方法を探しています。(仮想IPアドレスを使って避けるという横暴(?)な方法もあるのですが、最終的にGoogle App Engineなどで公開したいので...正攻法はないものでしょうか。)
という訳で今のところcomputerに関連した論文を検索しているだけなので特に有用なスクリプトにはなっておりませんが、今のところの出力はこんな感じです。
キーワード「Computer」に関連した論文の関係を図示。ボット検出をくぐれたらGUIも整備することにします。
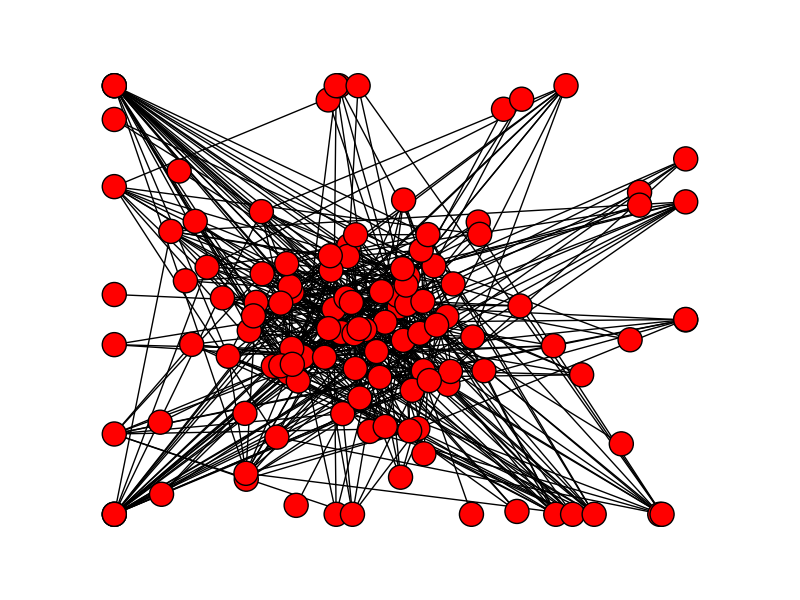
BeautifulSoup, networkxとmatplotlibをダウンロードする必要があります。
入力は論文の題名、URL か適当なキーワードにして、出力は関連する論文をグラフにまとめたものの予定。
作りかけなのはGoogle Scholarのボット検出に引っかかってしまうからです。今は引っかからないように毎回のアクセスに10~20秒時間をおいていますが、そうするとあまり大きな検索をすることが出来ません。大きな検索が出来ないとなると面白い結果が出せないので、ボット検出を避ける(なるべく穏便な)方法を探しています。(仮想IPアドレスを使って避けるという横暴(?)な方法もあるのですが、最終的にGoogle App Engineなどで公開したいので...正攻法はないものでしょうか。)
という訳で今のところcomputerに関連した論文を検索しているだけなので特に有用なスクリプトにはなっておりませんが、今のところの出力はこんな感じです。
キーワード「Computer」に関連した論文の関係を図示。ボット検出をくぐれたらGUIも整備することにします。
BeautifulSoup, networkxとmatplotlibをダウンロードする必要があります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 | # Parser from bs4 import BeautifulSoup import urllib2 # Network and Visualizing import networkx as nx import matplotlib.pyplot as plt # For polite bot import time import random import datetime url = "http://scholar.google.com" class CitationGraph: def __init__(self, title=''): self.g = nx.Graph() def add_result(self, result): self.g.add_node(result.title) for paper in result.papers: self.g.add_node(paper.title, paper = paper) self.g.add_edge(result.title, paper.title) def draw(self, path): nx.draw(self.g) plt.savefig(path + ".png") """ def extract(self, least_citations): if node['citations'] < least_citations: self.g.remove(node) """ """ The information of papers gain from specific URL. It also contains information about the context of the results. (ex. Cited or Related to the paper or a word search result) """ class Result: def __init__(self, query, title='', depth=1): self.title = title if 'cited' in query: context = 'cited' elif 'related' in query: context = 'related' else: context = 'search' self.query = query self.papers = [] self.search(1) def search(self, depth=1): time.sleep(random.randint(10, 20)) data = opener.open(url + self.query).read() soup = BeautifulSoup(data) for paper in soup.find_all('div', {'class' : 'gs_r'}): title = paper.find('div', {'class' : 'gs_ri'}).find('a').get_text() author = paper.find('div', {'class' : 'gs_a'}).get_text() abst = paper.find('div', {'class' : 'gs_rs'}).get_text() for link in paper.find_all('a'): if 'Cited' in link.get_text(): cited_link = link.get('href') citations = int(link.get_text().strip('Cited by ')) p = Paper(title, author, abst, cited_link, citations) self.papers.append(p) def print_papers(self): for paper in self.papers: paper.print_data() class Paper: def __init__(self, title, author, abst, cited_link, citations=0): self.title = title self.author = author self.abst = abst self.cited_link = cited_link self.citations = citations def print_data(self): print(self.title) print(self.author) print(self.abst) print(self.citations) print(self.cited_link) print('\n') """ Main Function """ opener = urllib2.build_opener() opener.addheaders = [('User-agent', 'Mozilla/5.0')] query = "/scholar?hl=en&q=computer&btnG=&as_sdt=1%2C5&as_sdtp=" r = Result(query, 'computer') r.print_papers() c = CitationGraph() c.add_result(r) for paper in r.papers: r2 = Result(paper.cited_link, paper.title) r2.print_papers() c.add_result(r2) t = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") c.draw('whole' + t) plt.show() |
2014年7月22日火曜日
知覚の諸問題

(SYNAPSEより)
Cognitive Neuroscience: The biology of the mind
Michael S. Gazzaniga, Richard B. Ivry and George R. Mangun
より5章Sensation and Perceptionの考察をまとめましたので、宜しければ。
文字認識とかでニューラルネットワークが使われますが、そこでのテクニックの多くは実際の人間の知覚を参考にしているところが多くあるのですね。
こういった認知科学の分野は、脳を分割していっても博物学的になるだけで面白い問題はないんじゃないかと思っていたんですが、意外と人間の脳というのは局所性があり、知能と「物質」を結びつけることができるようですね。
クオリアとかの主観的体験は観測することが出来ませんが、こういう機能論的な意味でのsensationを理解することはその礎になるのでしょう。
図表は全て上記論文より引用
2014年7月14日月曜日
マルチコアマシン環境における並列最良探索アルゴリズム
Best-First Heuristic Search for Multicore Machinesという論文をまとめたスライドです。
Ethan Burns, Sofia Lemons, Wheeler Ruml and Rong Zhou. (2010). Best-First Heuristic Search for Multicore Machines. Journal of Artificial Intelligence Research 39(2010) 689-743
内容は並列最良探索です。A*探索などの基本的な探索アルゴリズムを知っていることを前提としています。
よければどうぞ。
Ethan Burns, Sofia Lemons, Wheeler Ruml and Rong Zhou. (2010). Best-First Heuristic Search for Multicore Machines. Journal of Artificial Intelligence Research 39(2010) 689-743
内容は並列最良探索です。A*探索などの基本的な探索アルゴリズムを知っていることを前提としています。
よければどうぞ。
2014年7月12日土曜日
人工知能と生物知能
人工知能と生物知能は何が違うのだろうか。Turing は『Computing Machinery and Intelligence』(1950)において計算機が考えることが出来るかを議論することはあまりに無意味だと主張した。Turingは人工知能の定義を「そのシステムが人間であると人間が判定すること」としてTuring Testを提案した。これは外系からシステムを観察するという点で認識論的・機能論的な立場に立った定義であるだろう。ここで人間に知能があるという前提があることにも注意されたい。しかしながら、そもそも人間に知能があるということはどう解釈されるのだろうか。
1. Turing Test
2. 中国語の部屋
ちなみに、マニュアルをゲノムや遺伝子に仮定することが出来る。この場合マニュアルは外界からの刺激によって書き換わるといえる。しかしそれも受動的なプロセスで、部屋の人間に依拠する知能は認められないだろう。同様の議論がコンピュータでも言える。
1. Turing Test
そもそも知能はどう定義されるのだろうか。Turing TestはAlan Turingが1950年に提案した人工知能の判定方法である。方法としては、判定者である人間が隔離された場所にいる人間と機械のそれぞれと自然言語での対話を行う。この時機械は人間であるかのように振る舞う。判定者が人間と機械の区別が出来なかった場合にその機械はテストに合格し、人工知能として認められる。
しかしながらこのテストは様々な反論がある。例えば知能があるとはとても言えないシステムも真と判定されるという問題もあった。有名なものだとEliza Chat Botがある。面白いのでぜひ触ってみてほしい。このElizaを、知能だと思われるだろうか。もっとも重要な反論としては、Turing Testは、機械が自意識や認知能力がなくても知能であると判定しまうことがある。ここで「自意識や認知能力がある」とはstrong AIの立場に依る反論である(John Rogers Searle, 1980)。Searleは『Minds, Brains and Programs』(1980)においてstrong AIの立場を以下のように定義している。
「…強いAIによれば、コンピュータは単なる道具ではなく、正しくプログラムされたコンピュータには精神が宿るとされる」
weak AIはそれと対象的に、自意識や認知能力ではなく問題解決器として定義される。Searleは前述の著書において、中国語の部屋という思考実験でstrong AIを不可能と示した。
2. 中国語の部屋
中国語を理解できない人間を部屋の中に閉じ込める。外部とは遮断されており、唯一のやりとりは紙切れの交換で行われる。外から入れられる紙には中国語の文章が書かれているが、被験者は中国語を理解出来ないので、彼にはセマンティクスを持ったものとして認識されない。彼の課題はこの中国語の文章(彼にとっては意味のない記号列)に新しい記号を加えて外に戻すということである。ある記号列に対してどのような記号を書くかは部屋に置かれたマニュアルに全て書かれてある。
実は外の世界では、この紙切れは部屋の中の彼への「質問」であった。そして部屋の中からは「回答」が返ってくるのだ。質問を投げる外にいる人間は、「中には中国語を理解する人間がいる」と考える。しかし中にいる彼は中国語など分からず、ただただマニュアル通りに、理解もせず、しかし外にいる人間は「対話」をしているのだ。
さて、この思考実験が何をもたらすかを考えよう。
まずこの中国語の部屋は人工知能のメタファーである。即ちマニュアルがメモリにあるコードで、何も理解せずにマニュアル通りに行動する人間がプロセッサ、紙の交換がI/Oに当たる。如何に機械が知能を持って見えたとしても、プロセッサとメモリそれぞれに知能はなく、受動的に行動するのだからstrong AIは不可能であるとSearleは主張する。weak AIは外系(即ち部屋の外の質問者)から見て知能を持って見えるものを知能と定義するので、中国語の部屋はweak AIの定義からは知能であるといえる。Searleはこの議論を持って人工知能と人間の知能は区別されるという。しかしながら、中国語の部屋の議論は人間おいては生物の知能についても同様の言及をすることが出来るだろう。
3. 生物知能
生物に知能はあるのだろうか。あるとして、それはどういうメカニズムで生まれるのだろうか。まず、知能とは、心理学及びその周辺分野の研究者52人による『Mainstream Science on Intelligence』において以下のように定義されている。
A very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test-taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings—"catching on," "making sense" of things, or "figuring out" what to do.
この定義は記述的であるが人間の「知能」をよく表していると言えるだろう。(ここで知能とは心理学者らのそれであることに注意されたい。)さて、では生物一般にこのような特徴はあるのだろうか。例えば大腸菌に知能はあるのだろうか。上の定義と照らし合わせたとしても、大腸菌の個体に知能がなくても、大腸菌の個体群もしくは生態系は知能があると言えるだろう。生物は進化というメカニズムで知能を実装している。人間などの脊椎動物は相互作用のある細胞(例えばニューロン)を多く一個体に含むためその知能を個体ベースで持っているだけだと考えることが出来る。
大腸菌から人間まで同じ位相の「知能」を持っているとして、それをどう理解することが出来るのだろうか。先ほどの『Mainstream Science on Intelligence』は実はTuring Testと同様、機能主義的定義である。即ち、生物の知能も中国語の部屋と同様の議論が可能である。生物は外界からの刺激(紙切れ)に対して応答するが、それは「賢い」形態・行動ではなくただマニュアルに沿っているだけなのだと主張出来るだろう。
ちなみに、マニュアルをゲノムや遺伝子に仮定することが出来る。この場合マニュアルは外界からの刺激によって書き換わるといえる。しかしそれも受動的なプロセスで、部屋の人間に依拠する知能は認められないだろう。同様の議論がコンピュータでも言える。
結句
生物の知能と人工知能は同じ議論の下でしか定義することが出来ない。中国語の部屋の議論はstrong AIに対するアンチテーゼであるというより、strong intelligence一般に対するアンチテーゼである。転じて、生物に知能があると仮定すると、人工知能も知能があると言えるだろう。Turing Testとは、「人間に知能があるならば機械にも知能がある」という主張と考える方が厳密であるだろう。
登録:
投稿 (Atom)